Mitos de Hadoop y Datos Grandes
A estas alturas, todo el mundo ha oído hablar de Hadoop de Apache. Creado por Doug Cutting durante su gestión en Yahoo y nombrado por el elefante de peluche de su hijo, Hadoop es una biblioteca de software de código abierto que se utiliza para crear un entorno de computación distribuido. Hoy, es considerado como una de las más nuevas –y tal vez una de los mejores– tecnologías diseñadas para extraer valor de los "grandes datos".

Pero conforme Hadoop se convierte en un nombre familiar, también está adquiriendo una cierta forma mitológica. Philip Russom, analista de la industria y director de investigación del Instituto de Data Warehousing (TDWI) en Renton, Washington, quiere reventar esa forma de pensar por completo. En la Cumbre de Soluciones TDWI titulada “Analítica de big data para una ventaja negocios en tiempo real”, Russom presentó 12 hechos sobre Hadoop con la esperanza de disipar algunos de los mitos más comunes que circulan en toda la industria.
Hecho 1: Hadoop se compone de varios productos.

La gente puede hablar sobre Hadoop como si fuera esta enorme cosa singular, pero en realidad está formado por varios productos, dijo Russom.
"Hadoop es el nombre comercial de una familia de productos de código abierto", dijo Russom. "Esos productos se incuban y administran por el software de Apache”.
Cuando la gente normalmente piensa en Hadoop, piensa en su sistema de archivos distribuido Hadoop, o HDFS, que Russom llama una base sobre la cual poner capas de otros productos, como MapReduce.
Hecho 2: Hadoop es de código abierto, pero está disponible desde proveedores propietarios también.
Mientras que el software es de código abierto y se puede descargar de forma gratuita, proveedores como IBM, Cloudera y EMC Greenplum también han hecho disponible Hadoop a través de distribuciones especiales, dijo Russom.
Esas distribuciones tienden a venir con características adicionales, tales como herramientas administrativas no ofrecidas por Hadoop de Apache, así como soporte y mantenimiento. Algunos pueden burlarse de eso: ¿Por qué pagar por soporte cuando la comunidad de código abierto es gratuita? Pero Russom dijo que las distribuciones están haciendo a HDFS más potente para las empresas con departamentos de TI establecidos.
Hecho 3: Hadoop es un ecosistema, no un solo producto.
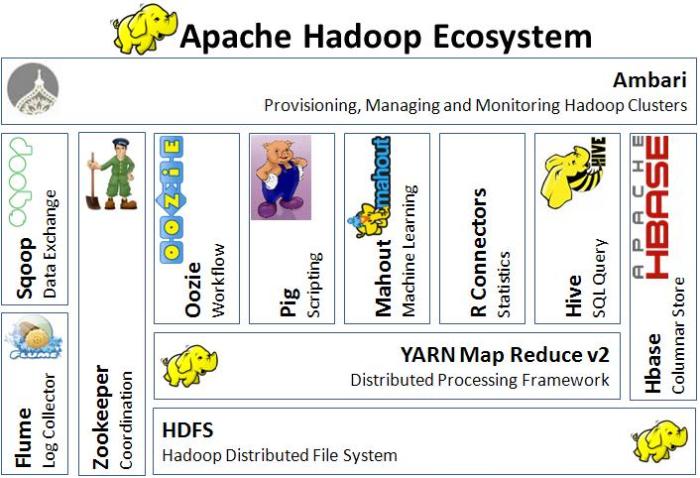
Los productos, que ayudan a extender la tecnología, están siendo desarrollados por el mercado de código abierto, así como por proveedores. Específicamente, Russom señala que los proveedores están proporcionando nuevos productos para ayudar a hacer que Hadoop se vea más relacional y estructurado.
"Tenemos esta larga historia de tener plataformas de información o plataformas de integración de datos y proporcionar interfaces para las plataformas más nuevas", dijo Russom. "Estamos viendo una cosa similar en este momento con Hadoop”.
Hecho 4: HDFS es un sistema de archivos, no un sistema de gestión de base de datos.
Ese lapso en la semántica es una de las mayores manías de Russom. Aunque puede gestionar colecciones de datos, ciertos atributos del sistema de gestión de base de datos están ausentes en Hadoop.
"Al igual que la posibilidad de acceder a datos de forma aleatoria gracias a los índices de consulta", dijo. "Esperamos estructura, que normalmente no se encuentra en la clase de tipos de datos con los que trata Hadoop”.
Hecho 5: Hive asemeja a SQL, pero no es SQL estándar.

Russom dijo que ese hecho puede ser un poco desconcertante, porque los negocios –y las herramientas que utilizan para acceder a los datos– tienden a estar basados en SQL. En su lugar, Hadoop utiliza Apache Hive y HiveQL, un lenguaje similar a SQL.
"He oído a gente decir, ‘Es tan fácil aprender Hive. Solo aprenda Hive’", dijo Russom. "Pero eso no resuelve el verdadero problema de la compatibilidad con las herramientas basadas en SQL”.
Russom cree que la cuestión de la compatibilidad es un problema a corto plazo, pero que actúa como una barrera para la comercialización de Hadoop.
Hecho 6: Hadoop y MapReduce están relacionados, pero que no se requieren mutuamente.

MapReduce fue desarrollado por Google antes de que existiera HDFS, dijo Russom. Además, añadió, algunos proveedores como MapR están vendiendo variaciones de MapReduce que no necesitan HDFS.
Russom, sin embargo, considera que el dúo es una buena combinación. La mayor parte del valor en HDFS, dijo, reside en las herramientas que se pueden superponer sobre el sistema de archivos distribuido.
Hecho 7: MapReduce proporciona control para la analítica, no analítica per se.

MapReduce es un motor de ejecución de propósito general, dijo Russom. Es propicio para el análisis de grandes datos, ya que puede tomar datos de codificación manual, procesarlos automáticamente en paralelo y luego asignar los resultados en un único conjunto. Pero MapReduce en realidad no hace la analítica en sí.
“Esta es una arquitectura MPP [procesamiento masivamente paralelo] básica, pero generalizado de modo que usted pueda lanzarle cualquier código que se pueda imaginar y solo tiene este talento para hacerlo paralelo", dijo Russom. "Eso es muy poderoso”.
Hecho 8: Hadoop se trata de la diversidad de datos, no solo el volumen de datos.
Algunos han encasillado a Hadoop como una tecnología diseñada para grandes volúmenes de datos, pero el valor real de Hadoop está en la forma en que puede manejar diversos datos, dijo Russom.
"Eso puede incluir las cosas que la mayoría de nuestros almacenes de datos no fueron diseñados para manejar", dijo. "Cosas como los datos semi-estructurados y totalmente no estructurados".
Hecho 9: Hadoop complementa un almacén de datos; raramente es un reemplazo.

La gestión de diversos tipos de datos ha inducido comentarios respecto a que los almacenes de datos están muriendo, pero Russom advierte contra estas afirmaciones radicales.
“¿Con qué frecuencia las personas reemplazan cosas en TI?”, preguntó. “Casi nunca”.
Los almacenes de datos siguen haciendo bien el trabajo para el que se construyeron, dijo, y Hadoop complementará al almacén de datos al convertirse en "un sistema de borde”.
"Vemos a los data warehouses y la arquitectura volviéndose cada vez más distribuidos, con más y más piezas agregadas a ellos", dijo.
Hecho 10: Hadoop permite muchos tipos de análisis, no solo analítica web.

Hadoop es a veces visto como la tecnología para los gigantes de internet, lo que plantea la cuestión de si se volverá comercial. Russom cree que lo será en parte, porque puede manejar una analítica más amplia.
Las compañías de ferrocarriles están, por ejemplo, usando sensores para detectar temperaturas inusualmente altas en vagones de ferrocarril, lo que puede indicar un fallo de obstaculización, dijo Russom, quien también citó ejemplos adicionales de las industrias robótica y de retail.
A pesar de que ve un futuro prometedor para Hadoop, Russom dijo que su adopción generalizada tomará años.
Hecho 11: Los grandes de datos no requieren Hadoop.

Los dos se han convertido en sinónimos, pero Russom dijo que Hadoop no es la única respuesta. En concreto, se refirió a productos de Teradata, Sybase IQ (ahora propiedad de SAP) y Vertica (ahora propiedad de Hewlett-Packard).
Además, algunas compañías han estado trabajando con big data por más tiempo de lo que Hadoop ha existido; por ejemplo, la industria de las telecomunicaciones con sus registros de detalle de llamadas, dijo Russom.
Hecho 12: Hadoop no es gratuito.

Si bien el software es de código abierto, el costo para el despliegue de Hadoop no lo es. Russom dijo que la falta de características tales como herramientas administrativas y soporte puede crear costos adicionales. Pero también carece de un optimizador y requerirá que los profesionales –que ganan más de 200,000 dólares– escriban código a mano dentro del entorno.
Eso no incluye los costos de hardware de un cluster Hadoop o los bienes raíces y el poder que se necesita para hacer operativo ese cluster.
"No vaya pensando que Hadoop es gratuito o incluso barato", dijo. "Hay un montón de costos que van con él”.

